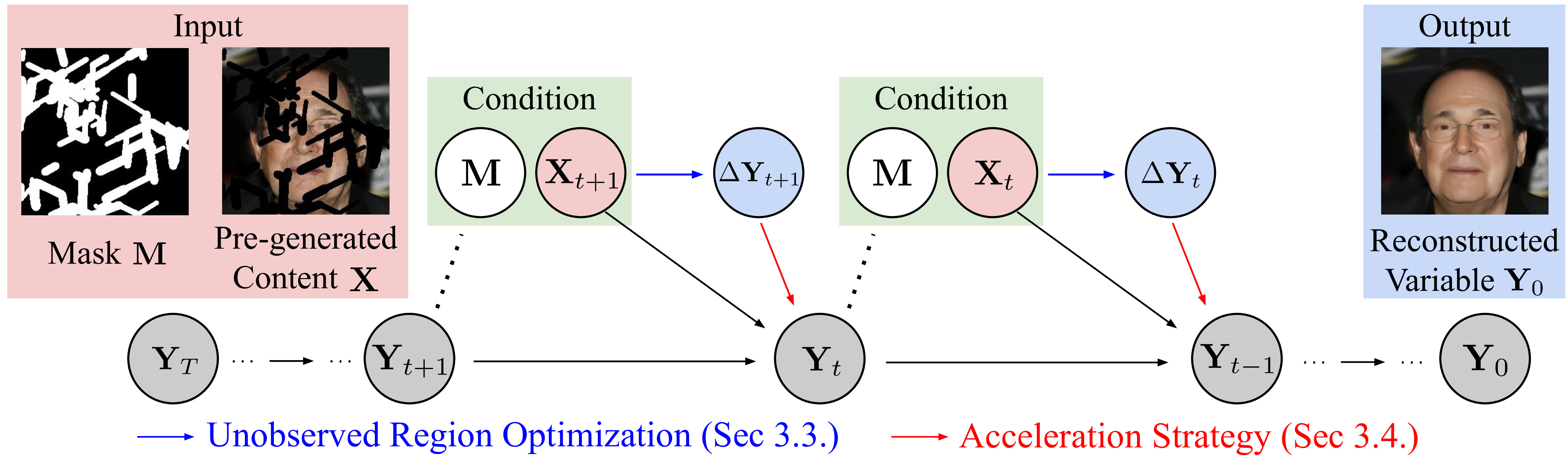
- Versatile content generation goes beyond generate-from-scratch settings by conditioning on partially observed or pre-generated inputs, covering inpainting, outpainting, motion completion, and 3D view-consistent generation.
- Training-based methods can achieve strong task-specific performance, but training is costly and the resulting models remain domain-limited; training-free synchronization methods are efficient, but often guide missing content only indirectly.
- ALM directly optimizes the unobserved region inside reverse diffusion by combining contextual consistency with full-sample realism, while keeping the pretrained model fixed.
- A one-step acceleration strategy makes this optimization practical while preserving strong performance.
TL;DR: ALM is a training-free sampling strategy that directly optimizes unobserved regions during diffusion sampling, turning pretrained models into versatile content generators.